
Architecting zero downtime for mental wellbeing AI at 1.5M requests a quarter
Wysa NewsAI / 10 min readWhen AI reliability is a clinical requirement and LLM provider moderation is the failure mode most teams don't anticipate.
Anand Gupta is Head of AI at Wysa, where he has led the design and deployment of multilingual production LLM systems serving 7M users globally in clinical mental health. His technical work covers model fine tuning, inference optimization, and AI safety, including neurosymbolic architectures that pair hard-coded clinical guardrails with small, quantized LLMs for offline deployment in low-resource settings. He is now shifting toward research and hands-on technical work in efficient inference and alignment, with continued applied projects in mental health.
What's at stake?
Wysa is an AI-guided self-help tool. Our users come to us during some of the hardest moments of their lives, dealing with anxiety, depression, grief, panic, and crisis. Wysa isn’t intended as a crisis support service, but when someone opens a conversation about a panic attack at 2 AM or is in the middle of a conversation about stress at work, the AI on the other end must recognise the gravity of the situation and respond immediately and accurately.
This is the context that shapes every infrastructure decision we make. A failed conversation request in a self-help conversation means someone in distress is staring at a loading spinner, or worse, an error message. The tolerance for failure in this domain is, for all practical purposes, zero.
Wysa processes over 3M AI invocations, and out of them, 700K AI requests per month need routing across multiple large language model providers and geographic regions. Each of these requests might involve a user mid-conversation about self-harm, a coaching session on managing workplace stress, or a guided sleep exercise. The content varies, but the requirement is to serve every request quickly.
That requirement, at that scale, is why we built a centralized stateful AI gateway. Not because we wanted architectural elegance (though that was a welcome result), but because we couldn’t risk the consequences of not having one. This paper describes what we built and what we learned in the process.
The multi-provider problem
Wysa relies on multiple LLM providers, each deployed across two to three geographic regions. That adds up to 15+ distinct routing targets for any given AI request. Each provider has a different API, different rate-limiting behavior, different failure modes, and a different latency profile. None of this is under our control.
Most companies scaling AI products end up with multiple providers, whether by choice (cost optimization, capability differences across models) or by necessity (no single provider offers the reliability guarantees a production system needs).
Mental wellbeing makes this harder in ways most teams don’t anticipate.
One such challenge is that each LLM provider applies content moderation and safety guardrails to their APIs. The moderation is designed to prevent harmful content generation across general-purpose use cases: consumer chatbots, writing assistants, coding tools, and search.
But in the mental wellbeing domain, user conversations routinely touch the exact topics those guardrails are designed to flag: self-harm, suicidal ideation, substance abuse, trauma, and emotional crisis. A prompt that is entirely appropriate in a clinical context can, and does, trigger provider-side moderation filters.
At the single-provider level, the result is that clinically valid prompts get rejected. At the multi-provider level, the problem is worse. If Provider A handles a self-help prompt correctly and then goes down, the obvious move is to fail over to Provider B. Except Provider B might block that same prompt. The fallback path just failed for a reason that has nothing to do with the general availability of the LLM, but more on this challenge later.
Building a multi-provider AI infrastructure in mental wellbeing is not the same as building it for general-purpose applications. The failure modes are different, and some of them are invisible if you are only thinking about uptime.
Design principles
The Wysa Stateful AI Gateway sits between all of Wysa’s products and the LLM providers they depend on. Every AI request flows through it. Here are the principles that shaped its design.
Proactive problem detection
Standard circuit breakers are reactive. They find out a provider is down because a user’s request fails, then they open the circuit to stop further requests. The user who triggered the discovery absorbs the impact.
In mental wellbeing care, that model doesn’t work. A broken session for a person in crisis is a failure to provide support, not a data point in a retry log.
So the gateway runs a health monitoring system that background-tests every provider and region combination. Every N seconds, the system sends lightweight test prompts and measures success rates, latency, and error frequency.
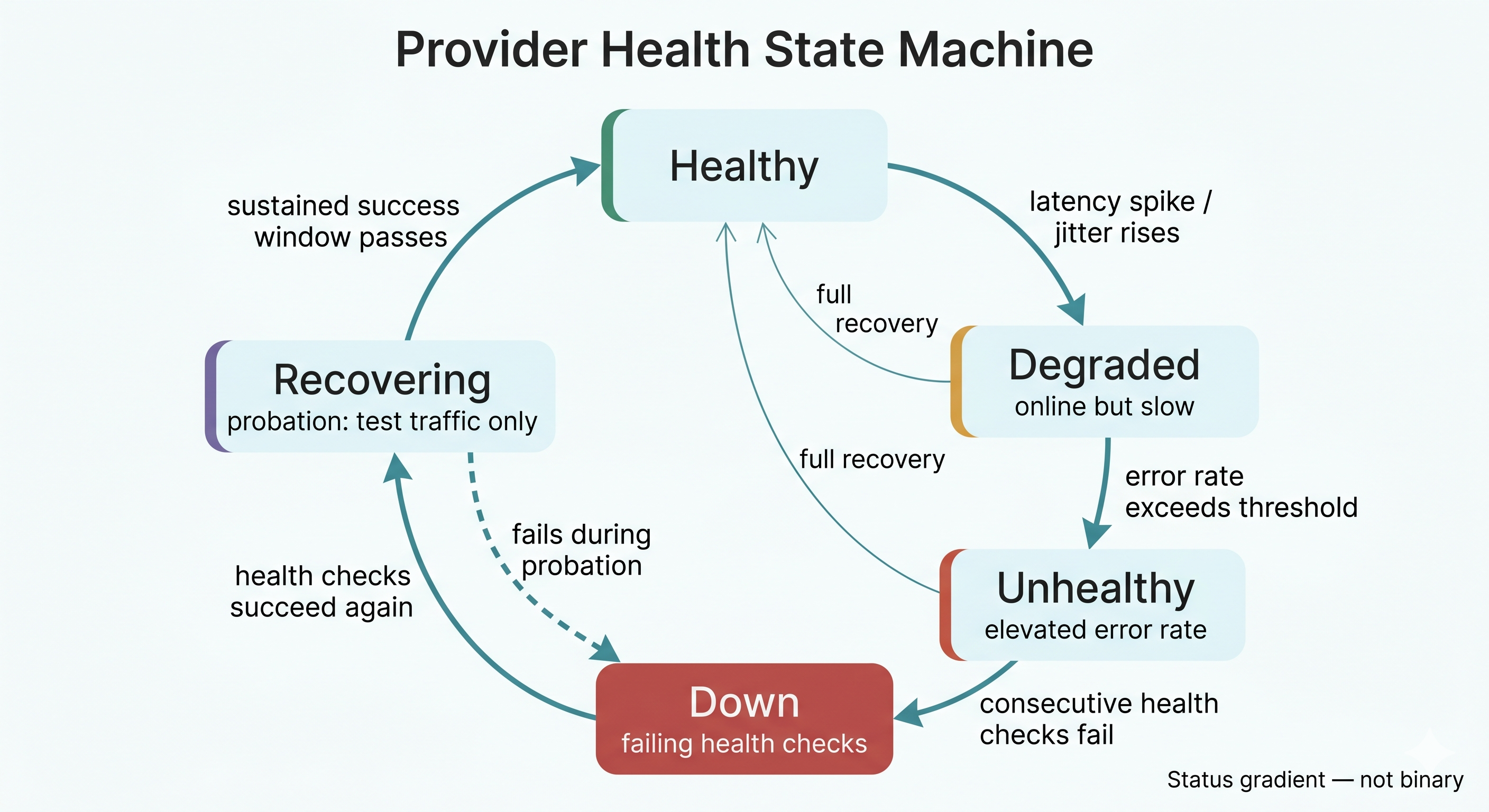
Instead of a binary healthy/unhealthy status, the system tracks a gradient: healthy, degraded, unhealthy, down, and recovering. A provider can be technically online but slow enough that routing traffic to it would hurt the user experience. A model coming back from an outage gets tested before it handles live traffic again.
The routing layer always has fresh health data. It never needs to send a real user’s request into the unknown to find out whether a provider is working, which also helps us with our compliance posture.
Fall back at every level
When a request comes in, the gateway builds a prioritized list of targets. The preferred model in the preferred region comes first. If that target is degraded or down (as determined by the health monitor, not by a failed request), the system moves to the same LLM model in another region. Then, a comparable LLM model from a different provider is targeted. Then to another provider entirely.
With multiple providers and multiple regions each, the fallback chain for a single request can be two to six targets deep before the system runs out of options. In practice, a request almost never reaches the third or fourth fallback. But the depth is there because the cost of exhausting the chain and returning an error is, in our domain, unacceptable.
All of this routing happens in milliseconds. The user sees a response. They do not see the decision tree that produced it.
Run guardrails once, call models in parallel
Of all the design choices, this one had the most measurable impact.
Wysa’s AI architecture is layered. A single content generation task often requires calling multiple models: one for classification, one for generation, one for safety checks, and so on. Before the gateway existed, each of these calls was made independently by the service that needed it. Each call ran input guardrails, made an API request, and ran output guardrails. The safety checks were thorough, but redundant. The same input was being validated three or four times.
The gateway changed this. Because all requests now flow through a single system, we were able to restructure the execution path. Input guardrails run once, at the point of entry. Model calls that can happen in parallel do happen in parallel. Output guardrails run once, on the aggregated result. The safety coverage is identical. The redundant work is gone.
That restructuring is the main reason the gateway reduced end-to-end latency by approximately one second, despite being an additional infrastructure layer. We did not just add a routing system but used this centralization as an opportunity to rethink how execution worked.
Separate monitoring, routing, and execution
The health monitor does not know how routing decisions are made. The routing logic does not execute requests. The execution layer does not make health assessments. Each component has one job and can be updated, scaled, or debugged independently. This decision of compartmentalising has paid off in practice. When we need to adjust health thresholds or add a new provider, the change is isolated to one component.
The moderation paradox in mental wellbeing AI
We want to spend time on a challenge that doesn’t get enough attention, and one we’ve had to work through directly.
LLM providers invest significantly in content moderation. Their systems are designed to prevent the generation of harmful content: graphic violence, hate speech, instructions for self-harm, and sexual content involving minors. These protections are important and exist for good reason. But the default moderation posture is calibrated for general-purpose use cases. A customer support chatbot, a coding assistant, a creative writing tool. In those contexts, a prompt mentioning suicide or self-harm is almost certainly something the model should refuse to engage with.
In mental wellbeing, the opposite is true. A user telling Wysa that they have been thinking about hurting themselves is not generating harmful content. They are reaching out for help. The appropriate response can not be a refusal or a content filter. It should be a clinically informed, empathetic reply that takes their distress seriously and connects them with the right resources, as needed.
During our initial integration with multiple providers, we discovered that clinically appropriate prompts were being flagged, filtered, or outright rejected by provider-side moderation. Anything touching suicidal ideation, self-harm, substance abuse, or severe emotional distress was hitting guardrails designed for very different contexts.
At the single-provider level, this was a solvable problem: work with the provider’s trust and safety team, demonstrate the clinical context, and negotiate a moderation configuration that preserves the safety intent while allowing mental health support content through.
At the multi-provider level, it became much harder. Each provider has different moderation sensitivities, different content taxonomies, and different thresholds for what gets flagged. A prompt that Provider A handles correctly might be blocked by Provider B. The fallback routing we built for reliability can be undermined by moderation inconsistency. Your failover breaks if the backup provider rejects the prompt.
Resolving this required engaging directly with the safety and trust teams at each of our providers. In each case, we had to demonstrate our clinical use case, explain why certain content categories needed different treatment in a mental health support context, and work through the configuration options available. These were not quick conversations. They required relationship-building, documentation of our clinical protocols, and in some cases, multiple rounds of moderation tuning before things worked correctly.
Additionally, providers update their moderation policies. New model versions sometimes ship with different safety behaviors. Each update requires us to validate that our self-help support content is still flowing correctly across all providers.
If you are building AI products in healthcare, crisis intervention, elder care, or any other sensitive domain, expect this friction. The default moderation posture of major LLM providers will get in your way. It is a cost you will not find in any pricing page or API documentation. If you are using multiple providers, you pay it multiple times. Budget accordingly, both in engineering time and in relationship-building with provider teams.
What 1.5 million requests taught us
The Wysa Stateful AI Gateway has been running in production since January 2026. In the first three months, it routed over 1.5 million LLM requests across all providers and regions.

Reliability at scale
Across 1.5 million requests, the gateway had zero attributable downtime. Every request that entered the system received a response.
We want to be transparent about what we learnt from monitoring this system since Jan 26. The health monitor has been running continuously since launch: tens of thousands of health checks, latency trend data, jitter measurements, and a record of the health state of every provider-region combination over time. That data accumulates value. It improves routing decisions, surfaces latency patterns we would not otherwise see, and gives us reason to believe the system will respond correctly when an outage does occur.
Performance: the unexpected gain
Another surprising result from the first two months was the latency improvement. Adding an infrastructure layer between our services and LLM providers made responses approximately one second faster at p95.
In most cases, more infrastructure means more overhead. Tell someone you added a routing and monitoring layer on top of their API calls, and they’ll assume you made things slower.
The gain came from two sources. First, guardrail deduplication: input and output safety checks that were previously running on every individual model call now run once. Second, parallel execution: model calls that were being made sequentially (because each service managed its own calls independently) are now fired simultaneously, where the dependency graph allows it.
Neither of these optimisations was possible in the pre-gateway architecture, where each service owned its own provider interactions. Centralizing the request path did not just add resilience but opened up optimizations we could not have made otherwise.
Operational clarity
Before the gateway, every service that needed an LLM call managed API keys separately, maintained separate provider configurations, and handled errors independently. Debugging a failed request meant figuring out which service made the call, which provider it went to, what the error was, and whether the same thing was happening elsewhere.
Now there is one entry point, one set of logs, one place to look. API keys are managed centrally. Provider configurations are maintained in one location. When something looks off, the debugging path is straightforward. For our operations team, this has been the most immediately valuable change.
Centralization also made instrumentation tractable. We track request volumes, latencies, error rates, and per-provider health state across all regions in Grafana dashboards. A Slack bot wired into the same telemetry pipeline pushes automated alerts the moment a provider degrades, an outage begins, or latency jitter crosses our thresholds. The on-call engineer typically learns about a provider issue before the provider's own status page reflects it.
Future Directions
Currently, our gateway focuses on a primary objective: verifying model availability and ensuring reliable routing. Looking ahead, we see significant opportunities for further optimization, such as implementing cost-aware routing to automatically select the most economical provider among those currently healthy.
Our goal in sharing these insights is to support the broader community of developers working in sensitive fields. Any organization developing therapeutic AI, tools for crisis intervention, or systems for clinical decision support will inevitably encounter the moderation hurdles we have detailed. By documenting our journey, we hope to enable others to bypass unnecessary trial and error and benefit from the lessons we have learned.
Disclaimer: Wysa is not designed to assist with crises such as abuse, severe mental health conditions that may cause feelings of suicide, harm to self, and any other medical emergencies. Wysa cannot and will not offer medical or clinical advice. It can only suggest that users seek advanced and professional medical help. Please reach out to your country-specific suicide hotline in case of an emergency.
You must be at least 18 years of age to use Wysa. If you are between 13 and 18 years of age, please read through the Terms of Service and Privacy Policy along with your parents or legal guardian to understand eligibility before use. Wysa is not designed to be used by children under 13.
Blog features AI-generated images.
Cover image by Teksomolika from Magnific.